
In this blog post, I’ll walk you through the process of recovering a Kubernetes cluster after losing two out of three control plane nodes. This scenario can be daunting, as it results in the loss of etcd quorum, rendering the API server inaccessible. However, with the right steps, you can restore your cluster to a working state, as I recently did with a cluster running Kubernetes v1.32.3, deployed with kubeadm, and using Keepalived for high availability (HA). Here’s how I did it.
Background
My cluster originally had three control plane nodes (cp1, cp2, cp3) and two worker nodes (node0, node1). The control plane nodes were configured with a Keepalived virtual IP (VIP) 10.0.0.101 for HA. Unfortunately, cp2 and cp3 were permanently lost, leaving only cp1 (IP: 10.0.0.1). This caused etcd to lose quorum, making the cluster’s API unavailable, even though the worker nodes continued running existing pods.
The goal was to restore the cluster with cp1 as the sole control plane node and then optionally rebuild HA by adding new nodes.
Prerequisites
- Access to the remaining control plane node (
cp1in my case). - SSH access with root privileges.
- Basic understanding of Kubernetes components (etcd, kube-apiserver, kubelet).
kubectl,kubeadm, and a container runtime (e.g., containerd) installed.- Backup of etcd data (optional but highly recommended).
Step-by-Step Recovery Process
Step 1: Assess the Situation
First, I confirmed the state of the cluster:
kubectl get nodesOutput: Error from server (Forbidden) or Timeout, indicating the API server was down.
Check etcd health:
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
endpoint healthOutput: https://127.0.0.1:2379 is unhealthy: failed to commit proposal: context deadline exceeded.
Check etcd members:
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member listOutput showed three members (cp1, cp2, cp3), but only cp1 был доступен.
Since etcd requires a majority (2 out of 3) for quorum, the cluster was stuck.
Step 2: Install etcdctl (if not available)
On cp1, etcdctl wasn’t installed by default. I downloaded it to match the etcd version (3.5.16):
wget https://github.com/etcd-io/etcd/releases/download/v3.5.16/etcd-v3.5.16-linux-amd64.tar.gz
tar -xvf etcd-v3.5.16-linux-amd64.tar.gz
mv etcd-v3.5.16-linux-amd64/etcdctl /usr/local/bin/
mv etcd-v3.5.16-linux-amd64/etcd /usr/local/bin/ # Optional, for manual etcd launch
chmod +x /usr/local/bin/etcdctl /usr/local/bin/etcd
etcdctl versionStep 3: Stop etcd
Since etcd runs as a static pod managed by kubelet, I stopped it by moving its manifest:
mv /etc/kubernetes/manifests/etcd.yaml /tmp/etcd.yaml.backupVerify it stopped:
crictl ps | grep etcdOutput should be empty.
Step 4: Backup etcd Data
Make a backup of the etcd data directory:
cp -r /var/lib/etcd /var/lib/etcd-backupStep 5: Force etcd to Run as a Single Node
Since removing cp2 and cp3 via member remove failed due to lack of quorum, force etcd to rebuild as a single-node cluster:
etcd --name cp1 \
--listen-client-urls https://127.0.0.1:2379,https://10.0.0.1:2379 \
--advertise-client-urls https://10.0.0.1:2379 \
--listen-peer-urls https://10.0.0.1:2380 \
--initial-advertise-peer-urls https://10.0.0.1:2380 \
--initial-cluster cp1=https://10.0.0.1:2380 \
--initial-cluster-state existing \
--data-dir /var/lib/etcd \
--cert-file=/etc/kubernetes/pki/etcd/server.crt \
--key-file=/etc/kubernetes/pki/etcd/server.key \
--trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt \
--peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt \
--peer-key-file=/etc/kubernetes/pki/etcd/peer.key \
--peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt \
--peer-client-cert-auth=true \
--client-cert-auth=true \
--force-new-cluster &If you see address already in use, stop any conflicting processes:
pkill etcd
crictl stop <etcd-container-id>Then rerun the command.
Check health:
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
endpoint healthOutput: https://127.0.0.1:2379 is healthy.
Verify members:
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member listOutput: Only cp1 remained.
Stop the manual instance:
pkill etcdStep 6: Update and Restart etcd Pod
Edit the etcd manifest to match the single-node configuration:
nano /tmp/etcd.yaml.backupEnsure:
- --initial-cluster=cp1=https://10.0.0.1:2380
- --initial-cluster-state=existingMove it back:
mv /tmp/etcd.yaml.backup /etc/kubernetes/manifests/etcd.yamlRestart kubelet:
systemctl restart kubeletVerify etcd (it can take some time for start, wait patiently):
crictl ps | grep etcd
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
endpoint healthStep 7: Restore API Server
Verify kube-apiserver manifest:
cat /etc/kubernetes/manifests/kube-apiserver.yamlConfirm --etcd-servers=https://127.0.0.1:2379. Restarted kubelet:
systemctl restart kubeletCheck:
crictl ps | grep kube-apiserver
kubectl get nodesStep 8: Clean Up Lost Nodes
Remove cp2 and cp3 from the cluster:
kubectl delete node cp2
kubectl delete node cp3Step 9: Verify Cluster
Final check:
kubectl get nodes
kubectl get pods -AThe cluster was back online with cp1 as the sole control plane node.
Optional: Restoring High Availability
To rebuild HA:
- Generate a certificate key:
kubeadm init phase upload-certs --upload-certs1.1. Jenerate token with:
kubeadm token create --print-join-command- Join new control plane nodes (e.g.,
cp4,cp5):
kubeadm join 10.0.0.101:6443 --token <token> --discovery-token-ca-cert-hash <hash> --control-plane --certificate-key <key>3. Verify nodes:
kubectl get node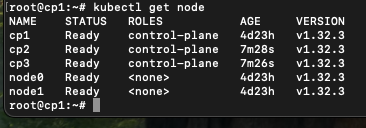
Update --initial-cluster in etcd.yaml on all nodes and restart kubelet
The --initial-cluster parameter in the etcd configuration defines the members of the etcd cluster. Initially, we forced etcd to run as a single node (cp1) with:
--initial-cluster=cp1=https://10.0.0.1:2380Now that cp2 and cp3 are back, you need to include them in the --initial-cluster list so etcd operates as a three-node cluster again, ensuring quorum and HA. Each control plane node runs its own etcd instance, and they must all agree on the cluster membership.
Assumptions
cp1: IP10.0.0.1cp2: IP10.0.0.2(based on earliermember listoutput)cp3: IP10.0.0.3(based on earliermember listoutput)- Each node’s etcd listens on its own IP at port
2380for peer communication.
Adjust these IPs if they’ve changed in your environment.
Step 1: Verify Current etcd Members
On cp1, check the current etcd membership:
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member listExpected output should now include cp1, cp2, and cp3 (since they’re back). If it still shows only cp1, we’ll need to add the others manually after updating the manifests.
Step 2: Update etcd.yaml on Each Node
You need to edit /etc/kubernetes/manifests/etcd.yaml on cp1, cp2, and cp3 to include all three nodes in --initial-cluster.
edit etcd.yaml manifest on all 3 control plane nodes:
nano /etc/kubernetes/manifests/etcd.yamlFind the command section and update --initial-cluster to:
- --initial-cluster=cp1=https://10.0.0.1:2380,cp2=https://10.0.0.2:2380,cp3=https://10.0.0.3:2380
- --initial-cluster-state=existingSave and exit.
Notes:
- Ensure
--namematches the node’s name (e.g.,--name=cp1oncp1,--name=cp2oncp2, etc.). - Verify that
--listen-peer-urlsand--initial-advertise-peer-urlsuse the correct IP for each node (e.g.,https://10.0.0.2:2380oncp2).
Step 3: Restart kubelet on Each Node
Restart kubelet to apply the changes. Do this one node at a time to maintain etcd quorum:
systemctl restart kubeletWait a few seconds (sometimes it can took longer), then check:
crictl ps | grep etcd
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
endpoint healthShould return healthy.
Step 4: Verify etcd Cluster
On any control plane node, check the cluster:
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member listExpected output:
<member-id-1>, started, cp1, https://10.0.0.1:2380, https://10.0.0.1:2379, false
<member-id-2>, started, cp2, https://10.0.0.2:2380, https://10.0.0.2:2379, false
<member-id-3>, started, cp3, https://10.0.0.3:2380, https://10.0.0.3:2379, falseCheck overall health:
etcdctl --endpoints=https://10.0.0.1:2379,https://10.0.0.2:2379,https://10.0.0.3:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
endpoint healthShould show all endpoints as healthy.
Step 5: Verify Kubernetes Cluster
kubectl get nodesEnsure all nodes are Ready. Check pods:
kubectl get pods -AConclusion
Recovering a Kubernetes cluster after losing control plane nodes is challenging but doable. The key was using --force-new-cluster to rebuild etcd as a single node, followed by aligning the manifests and restarting components. Regular etcd backups and HA planning can prevent such scenarios, but this guide proves recovery is possible even in dire situations.